

Step-by-Step Guide to ETL Using AWS Stack
Taking your business raw data into Datawarehouse for taking better business descions, using AWS ETL stack.

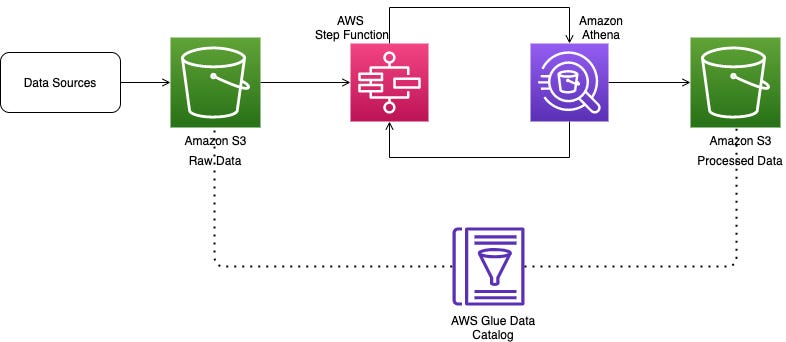
We all know how important is data for any business, but the data that we are getting from the sources are very raw and we cannot derive insights from it. That's where ETL pipelines come into picture, Where it seamlessly Extracts, transforms your data and loads it into datawarehouse for analytics, Machine learning and Data science team to build visualizations and models on top of it, for making right business descions. In this blog post I will provide an ETL pipeline model on the AWS stack.
In future post I will provide how it is done Azure and GCP as well.
The ETL Journey:
Imagine you have an e-commerce platform where your customers from all around the world can buy custom made handcrafted products from your city, and you need to process daily sales data, and see which country has intent purchase rate, from our website in order to analyze trends, track performance, generate reports, and using these reports you can take descions which products are getting sold more and in which country you are doing great and which areas you have to invest on to build and scale more.
Well, how can you do this and who will do this? That’s where a data engineer comes into the place to do the deep work getting your data out of the box and giving it analytics teams to build dashboards and models. Let’s dive into the steps now.
1. Extract:
Data Source: All your data is stored in Website server logs containing details of each transaction (product purchased, price, customer information, etc.).
Tool: AWS Kinesis Firehose: This Streams real-time data from your website directly to S3 bucket.
2. Transform:
Data Location: Raw sales data stored in S3.
Tool: AWS Glue:
Crawler: This discovers the schema of the incoming data automatically,
Job with Spark DataFrame API: It handles massive data volumes efficiently, with it’s distributed computing power of Spark.Cleansing of data (e.g., removes invalid entries, filters unwanted fields), and aggregates sales by product, category.
3. Load:
Target: Two destinations we will take.
Amazon Redshift: It stores aggregated sales data for fast and efficient analytics.
Amazon Athena: It stores raw sales data for ad-hoc querying and exploration.
Tools:
AWS Glue Job: Loads aggregated data into Redshift using Redshift Data Connector.
AWS S3 Partitioning: Organizes raw data in Athena based on date or other relevant criteria for efficient querying.
Additional Considerations:
Error Handling: We can Implement mechanisms to handle errors during data extraction, transformation, or loading. We can implement retry logic and dead lock queues here.
Monitoring and Logging: We can setup CloudWatch to monitor data pipeline health, track job execution times, and identify any errors or issues.
Scheduling: Use AWS Step Functions or CloudWatch Events to schedule your ETL pipeline to run daily on a particular time or based on any specific triggers.
Cost Optimization: We can Implement cost-effective options like reserved instances for Redshift or serverless options like AWS Lambda for specific transformations.
Benefits of using AWS Stack:
Scalability: Handles large data volumes with automatic scaling to meet demands.
Serverless: Reduces infrastructure management overhead.
Integration: Seamless integration between different AWS services for smooth data flow.
Security: Offers robust security features and access control mechanisms.
This diagram depecits the whole in a single picture.

This is how we can build ETL pipelines using AWS stack for taking raw data to a structured format for enabling business teams to make better descions. In the coming posts I will cover the common tools used for ETL in Azure and GCP.